
Metadata Extraction – Extract Document Properties, Tags & File Information | Transfonic
Instantly Extract Metadata from Documents, PDFs, Images, and Files with AI-Powered Precision
“Unlock valuable insights hidden inside your files with Transfonic's Metadata Extraction tool. Automatically extract document properties, author information, timestamps, tags, and structured metadata from PDFs, images, and business documents using AI-powered processing and OCR technology.”
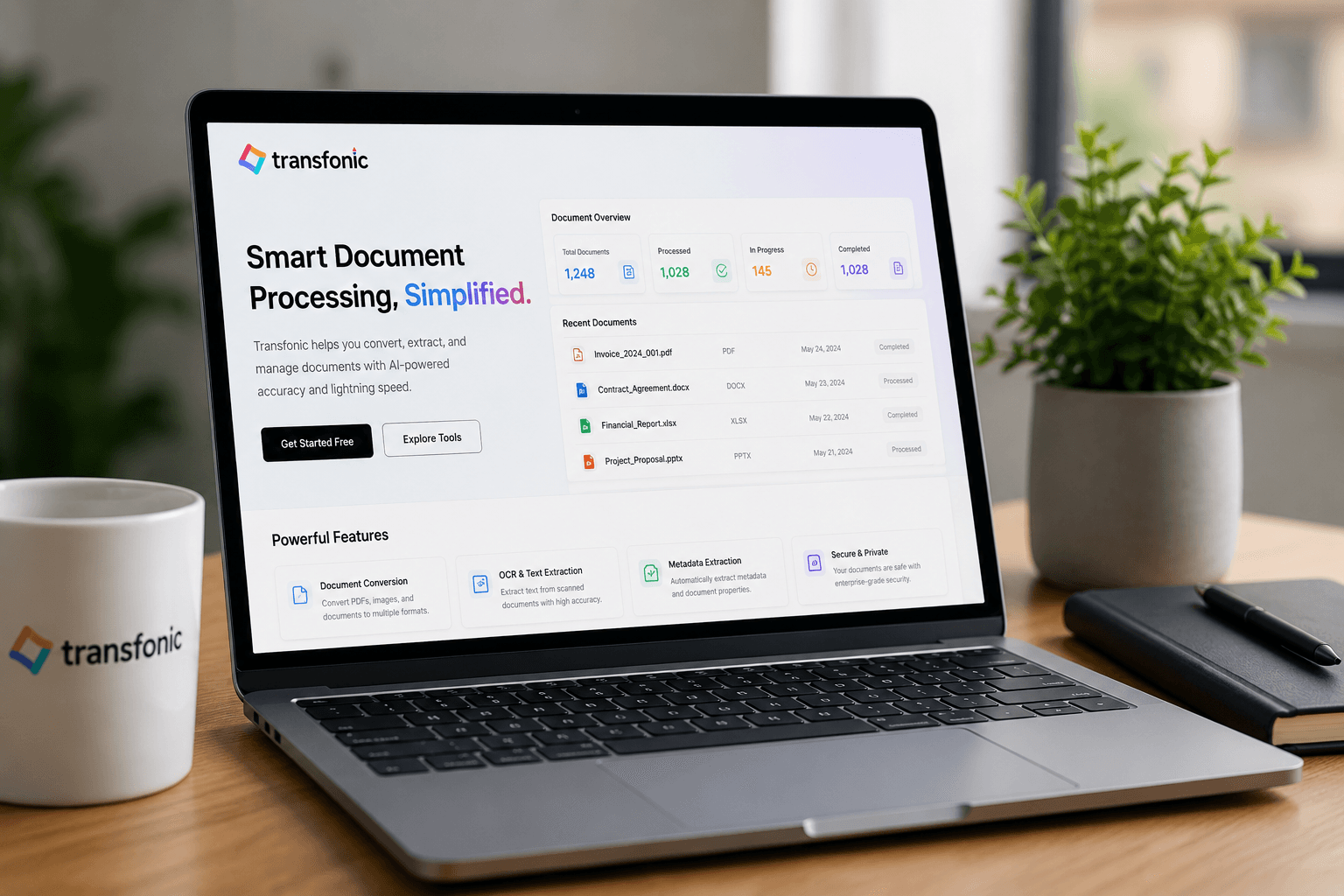
In today's digital world, documents contain much more than visible text. Every PDF, image, spreadsheet, and document often includes valuable metadata such as creation dates, author details, file properties, keywords, tags, modification history, and embedded information. Manually identifying and organizing this data can be time-consuming and inefficient. Transfonic's Metadata Extraction tool simplifies this process by automatically discovering and extracting important metadata from various file formats.
Our advanced AI-powered engine is designed to process multiple document types, including PDFs, Word documents, Excel files, PowerPoint presentations, scanned images, and other digital files. By combining intelligent document analysis with Optical Character Recognition (OCR), Transfonic can identify both visible and hidden information within documents and transform it into structured, usable data.
Metadata extraction is particularly valuable for businesses that manage large volumes of documents. Legal firms can organize contracts and records more efficiently, financial institutions can automate document classification, and healthcare organizations can streamline patient document management. Content creators and publishers can also use metadata extraction to maintain file consistency and improve document searchability.
Transfonic offers a high-speed and secure document processing platform. ON-Premise Webbase Files Quick hybrid Analyze files saccordingly to algorithmic Identifiy the file Attribute Author Definition date various embedded Tags.Doc Title among others This extracted information can then be utilized for indexing, workflow automation, compliance management and intelligent document organization.
Increased productivity one of the major benefits of metadata extraction. This saves organisations the time of having to sift through hundreds or thousands of files with a manual review process, automating the collection of key details in seconds. This not only relieves administrative burden but also reduces errors and improves the accuracy of the data.
Transfonic is also about security and privacy. While processing documents, safe technological environment that protects sensitive information while providing accurate results is used. Your business can process documents without fear of your data being compromised during the extraction workflow.
Whether you are handling corporate records, cataloging digital assets and metadata files, processing invoices, or creating document automation systems—Transfonic's Metadata Extraction tool gets the job done easily. Our platform makes hidden document properties structured and actionable data for your organisation to enhance productivity, searchability, and smarter data-driven decisions.
Experience intelligent metadata extraction with Transfonic and unlock the full value of your documents through automated, AI-powered document processing.
Key Benefits
Faster Document Organization
Automatically extract file metadata and document properties within seconds, reducing manual review time and improving document management efficiency.
Improved Search and Discovery
Extracted metadata makes files easier to categorize, index, and search, helping teams quickly locate important information across large document repositories.
Reduced Manual Errors
AI-powered extraction eliminates repetitive manual data entry and minimizes inaccuracies in document classification and information processing.
Seamless Workflow Automation
Convert metadata into structured data that can be integrated with business systems, document management platforms, and automated workflows.
Multi-Format Compatibility
Process PDFs, Word documents, spreadsheets, presentations, images, and scanned files using a single metadata extraction solution.
Secure and Reliable Processing
Enterprise-grade security ensures sensitive document information is processed safely while maintaining privacy and compliance standards.
What's New in this Release
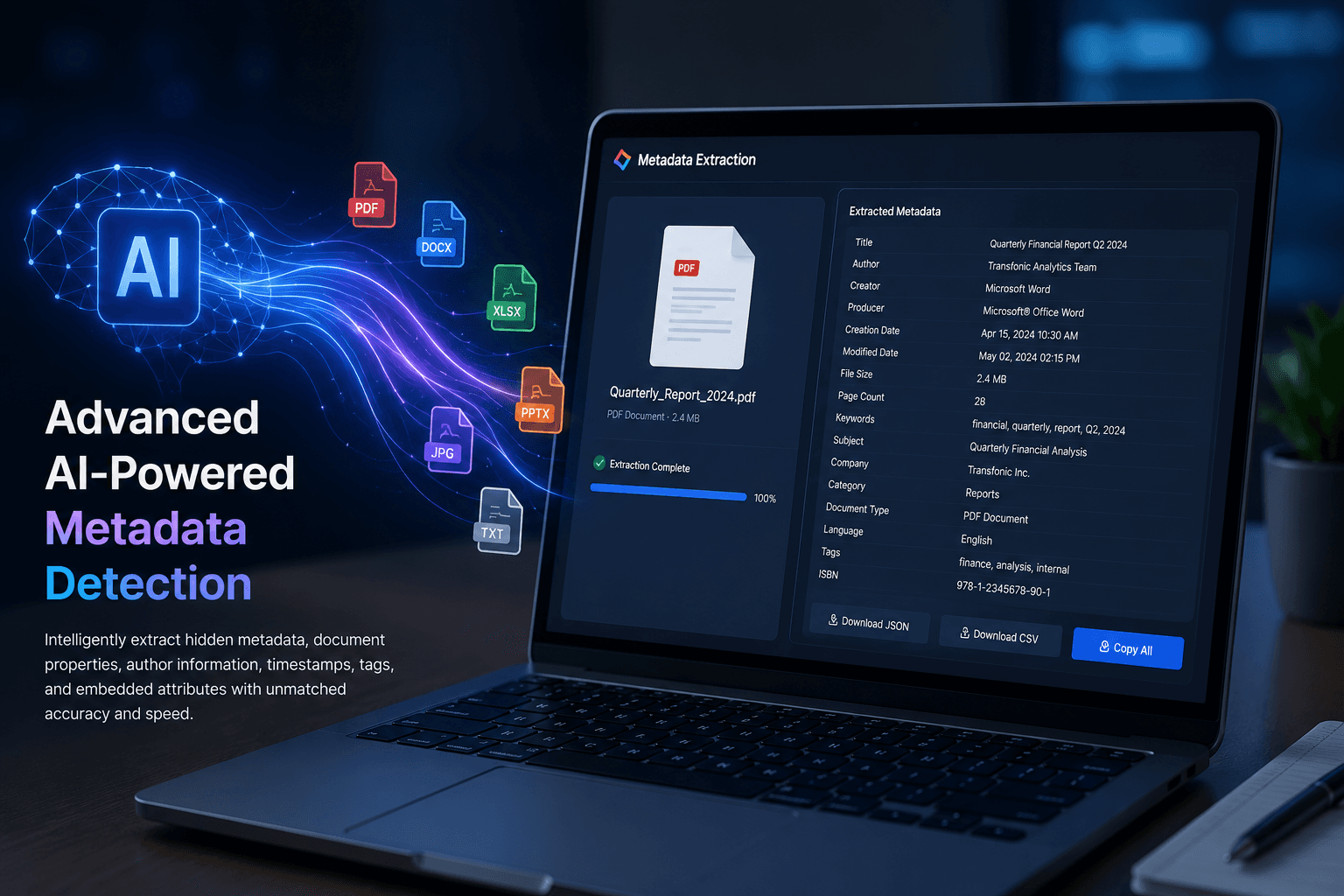
Advanced AI-Powered Metadata Detection
Transfonic now uses enhanced AI algorithms to automatically detect and extract hidden metadata from PDFs, Word documents, images, spreadsheets, and other file formats. The upgraded engine identifies document properties, author information, timestamps, tags, and embedded attributes with greater accuracy and speed, reducing manual processing efforts.
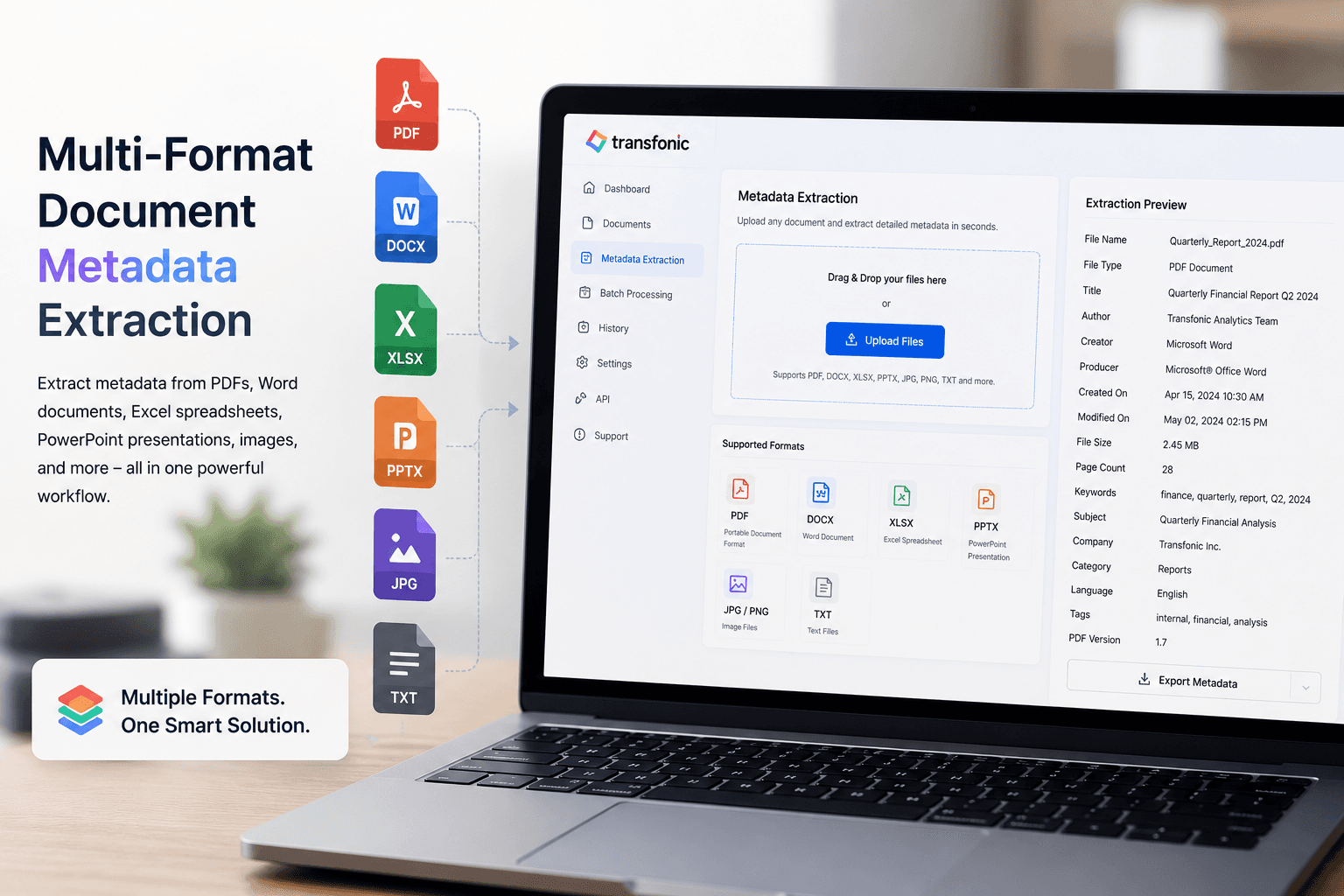
Multi-Format Document Metadata Extraction
Our latest release expands support for multiple document types, including PDF, DOCX, XLSX, PPTX, PNG, JPG, and scanned documents. Users can now extract metadata and file information from diverse formats within a single workflow, improving document organization and automation capabilities.
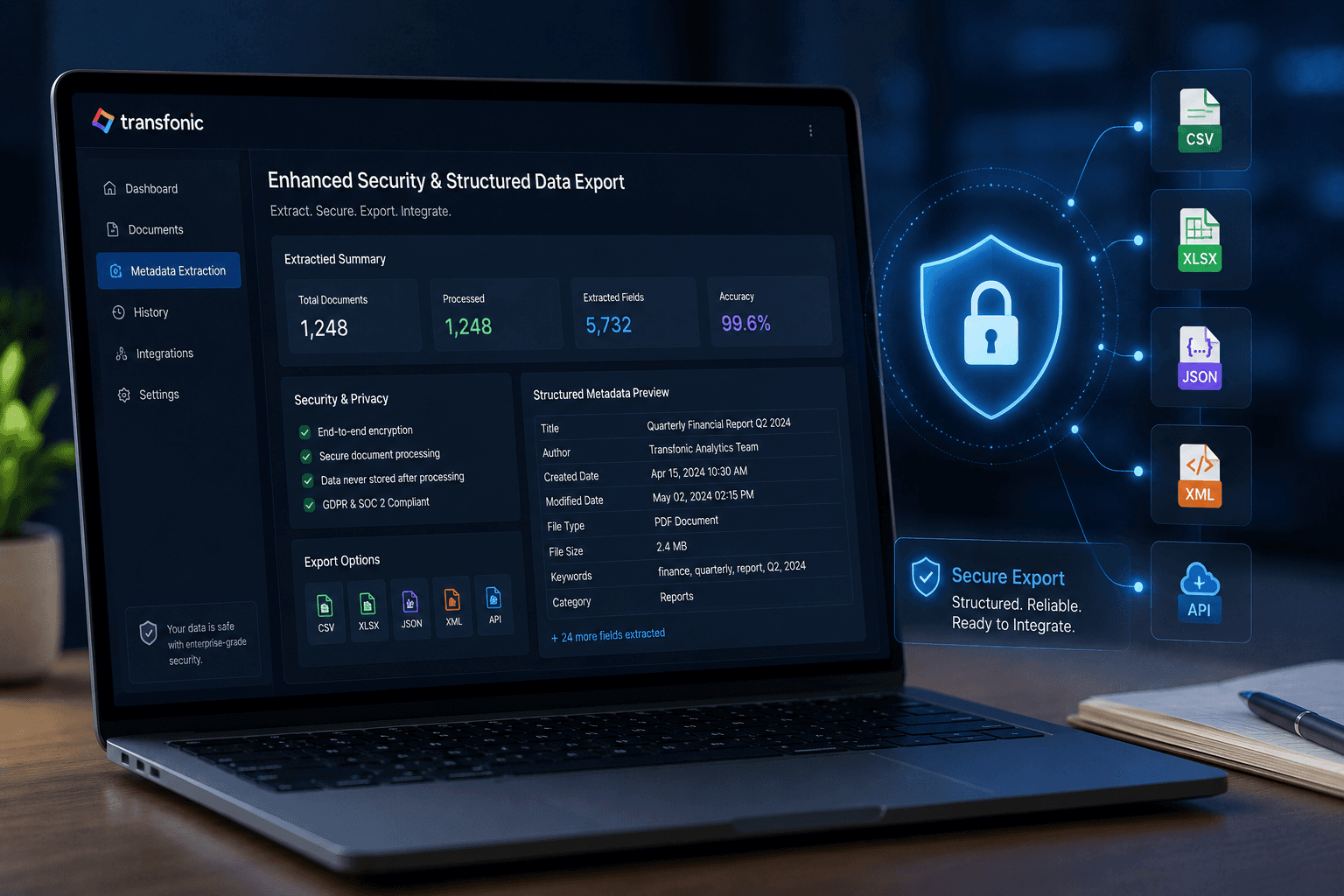
Enhanced Security and Structured Data Export
This update introduces stronger security protections and improved export options. Extracted metadata can now be organized into structured formats for reporting, indexing, and workflow integration while maintaining enterprise-grade privacy and secure document processing standards.
Key Features
AI Metadata Extraction
Automatically identifies hidden document properties, author information, timestamps, tags, and embedded attributes.
Multi-Format File Support
Extract metadata from PDF, DOCX, XLSX, PPTX, JPG, PNG, TXT, and other commonly used file formats.
OCR-Powered Analysis
Uses Optical Character Recognition to analyze scanned documents and images alongside file metadata.
Structured Data Export
Export extracted metadata into organized formats such as JSON, CSV, XML, and API-ready outputs.
Batch Document Processing
Process multiple documents simultaneously to save time and improve productivity for large-scale operations.
Secure Cloud Processing
Protects sensitive files with secure processing methods and privacy-focused document handling.
Core Use Cases
Legal Document Management
Extract metadata from contracts and legal files to improve indexing, auditing, and document retrieval.
Financial Record Processing
Organize invoices, reports, and financial documents by automatically identifying file properties and metadata.
Digital Asset Management
Categorize images, presentations, and media files using extracted metadata for faster content management.
Enterprise Document Automation
Convert document metadata into structured information that powers automated business workflows and integrations.
Compliance and Audit Preparation
Track document creation dates, modifications, authorship details, and file history to support compliance requirements.
Knowledge and Archive Management
Build searchable document repositories by extracting metadata from historical records and large digital archives.